Устранение проблем с производительностью UPDATE с помощью узких и широких планов в SQL Server
Применяется к: SQL Server
В UPDATE некоторых случаях оператор может выполняться быстрее, а в других — медленнее. Существует множество факторов, которые могут привести к такой дисперсии, включая количество обновленных строк и использование ресурсов в системе (блокировка, ЦП, память или ввод-вывод). В этой статье рассматривается одна конкретная причина отклонения: выбор плана запроса, сделанного SQL Server.
Что такое узкие и широкие планы?
При выполнении инструкции UPDATE для столбца кластеризованного индекса SQL Server обновляет не только сам кластеризованный индекс, но и все неклатеризованные индексы, так как неклатеризованные индексы содержат ключ индекса кластера.
SQL Server можно выполнить обновление двумя способами:
Узкий план. Обновление некластикционного индекса вместе с обновлением ключа кластеризованного индекса. Такой простой подход прост для понимания; обновите кластеризованный индекс, а затем обновите все некластикционные индексы одновременно. SQL Server обновит одну строку и перейдет к следующей, пока все не будут завершены. Такой подход называется обновлением узкого плана или обновлением Per-Row. Однако эта операция является относительно дорогостоящей, так как порядок обновляемых данных некластикционного индекса может быть не в порядке, указанном в порядке данных кластеризованного индекса. Если в обновлении задействовано много страниц индекса, при наличии данных на диске может возникнуть большое количество случайных запросов ввода-вывода.
Широкий план. Для оптимизации производительности и уменьшения числа случайных операций ввода-вывода SQL Server может выбрать широкий план. Он не выполняет обновление неклатеризованных индексов вместе с кластеризованным индексом вместе с обновлением кластеризованного индекса вместе. Вместо этого он сначала сортирует все неклатеризованные данные индекса в памяти, а затем обновляет все индексы в этом порядке. Такой подход называется широким планом (также называется обновлением Per-Index).
Ниже приведен снимок экрана с узкими и широкими планами:

Когда SQL Server выбирает широкий план?
Чтобы выбрать широкий план, SQL Server должны соблюдаться два критерия:
- Количество затронутых строк превышает 250.
- Размер конечного уровня некластичных индексов (число страниц индекса * 8 КБ) составляет не менее 1/1000 параметра max server memory.
Как работают узкие и широкие планы?
Чтобы понять, как работают узкие и широкие планы, выполните следующие действия в следующей среде:
- SQL Server 2019 CU11
- Максимальное число памяти сервера = 1500 МБ
Выполните следующий скрипт, чтобы создать таблицу
mytable1с 41 501 строкой, одним кластеризованным индексом в столбцеc1и пятью неклатеризованными индексами в остальных столбцах соответственно.CREATE TABLE mytable1(c1 INT,c2 CHAR(30),c3 CHAR(20),c4 CHAR(30),c5 CHAR(30)) GO WITH cte AS ( SELECT ROW_NUMBER() OVER(ORDER BY c1.object_id) id FROM sys.columns CROSS JOIN sys.columns c1 ) INSERT mytable1 SELECT TOP 41000 id,REPLICATE('a',30),REPLICATE('a',20),REPLICATE('a',30),REPLICATE('a',30) FROM cte GO INSERT mytable1 SELECT TOP 250 50000,c2,c3,c4,c5 FROM mytable1 GO INSERT mytable1 SELECT TOP 251 50001,c2,c3,c4,c5 FROM mytable1 GO CREATE CLUSTERED INDEX ic1 ON mytable1(c1) CREATE INDEX ic2 ON mytable1(c2) CREATE INDEX ic3 ON mytable1(c3) CREATE INDEX ic4 ON mytable1(c4) CREATE INDEX ic5 ON mytable1(c5)Выполните следующие три инструкции T-SQL
UPDATEи сравните планы запросов:-
UPDATE mytable1 SET c1=c1 WHERE c1=1 OPTION(RECOMPILE)— одна строка обновлена -
UPDATE mytable1 SET c1=c1 WHERE c1=50000 OPTION(RECOMPILE)— Обновлено 250 строк. -
UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE)— обновлена 251 строка.
-
Проверьте результаты на основе первого критерия (пороговое значение для затронутого количества строк — 250).
На следующем снимку экрана показаны результаты на основе первого критерия:

Как и ожидалось, оптимизатор запросов выбирает узкий план для первых двух запросов, так как количество затронутых строк меньше 250. Для третьего запроса используется широкий план, так как число затронутых строк составляет 251, что больше 250.
Проверьте результаты на основе второго критерия (размер памяти конечного индекса составляет не менее 1/1000 от параметра max server memory).
На следующем снимку экрана показаны результаты на основе второго критерия:

Для третьего
UPDATEзапроса выбирается широкий план. Но индексic3(в столбцеc3) не отображается в плане. Проблема возникает из-за того, что не выполняется второе условие — размер индекса конечных страниц по сравнению с параметром max server memory.Тип данных столбца , и — , а тип данных столбца
c3—char(20).char(30)c4c4c2Размер каждой строки индексаic3меньше, чем у других, поэтому количество конечных страниц меньше, чем у других.С помощью динамической функции управления (DMF)
sys.dm_db_database_page_allocationsможно вычислить количество страниц для каждого индекса. Для индексовic2,ic4, иic5каждый индекс содержит 214 страниц, и 209 из них являются конечными страницами (результаты могут немного отличаться). Объем памяти, потребляемой конечными страницами, составляет 209 x 8 = 1672 КБ. Таким образом, соотношение равно 1672/(1500 x 1024) = 0,00108854101, что больше 1/1000.ic3Однако только 161 страница, 159 из которых являются конечными страницами. Соотношение равно 159 x 8/(1500 x 1024) = 0,000828125, что меньше 1/1000 (0,001).Если вставить больше строк или уменьшить максимальное количество памяти сервера в соответствии с критерием, план изменится. Чтобы сделать размер конечного уровня индекса больше 1/1000, можно немного уменьшить параметр max server memory до 1200, выполнив следующие команды:
sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'max server memory', 1200; GO RECONFIGURE GO UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE) --251 rows are updated.В этом случае 159 x 8/(1200 x 1024) = 0,00103515625 > 1/1000. После этого изменения
ic3объект появится в плане.Дополнительные сведения о
show advanced optionsсм. в разделе Использование Transact-SQL.На следующем снимку экрана показано, что при достижении порогового значения памяти широкий план использует все индексы:




Является ли широкий план быстрее, чем узкий план?
Ответ заключается в том, что это зависит от того, кэшируются ли страницы данных и индексов в буферном пуле.
Данные кэшируются в буферном пуле
Если данные уже находятся в буферном пуле, запрос с широким планом не обязательно обеспечивает дополнительные преимущества производительности по сравнению с узкими планами, так как широкий план предназначен для повышения производительности ввода-вывода (физические операции чтения, а не логические операции чтения).
Чтобы проверить, работает ли широкий план быстрее узкого плана, если данные содержатся в буферном пуле, выполните следующие действия в следующей среде:
SQL Server 2019 CU11
Максимальная память сервера: 30 000 МБ
Размер данных составляет 64 МБ, а размер индекса — около 127 МБ.
Файлы базы данных находятся на двух разных физических дисках:
- I:\sql19\dbWideplan.mdf
- H:\sql19\dbWideplan.ldf
Создайте другую таблицу ,
mytable2выполнив следующие команды:CREATE TABLE mytable2(C1 INT,C2 INT,C3 INT,C4 INT,C5 INT) GO CREATE CLUSTERED INDEX IC1 ON mytable2(C1) CREATE INDEX IC2 ON mytable2(C2) CREATE INDEX IC3 ON mytable2(C3) CREATE INDEX IC4 ON mytable2(C4) CREATE INDEX IC5 ON mytable2(C5) GO DECLARE @N INT=1 WHILE @N<1000000 BEGIN DECLARE @N1 INT=RAND()*4500 DECLARE @N2 INT=RAND()*100000 DECLARE @N3 INT=RAND()*100000 DECLARE @N4 INT=RAND()*100000 DECLARE @N5 INT=RAND()*100000 INSERT mytable2 VALUES(@N1,@N2,@N3,@N4,@N5) SET @N+=1 END GO UPDATE STATISTICS mytable2 WITH FULLSCANВыполните следующие два запроса, чтобы сравнить планы запросов:
update mytable2 set c1=c1 where c2<260 option(querytraceon 8790) --trace flag 8790 will force Wide plan update mytable2 set c1=c1 where c2<260 option(querytraceon 2338) --trace flag 2338 will force Narrow planДополнительные сведения см. в разделах флаг трассировки 8790 и флаг трассировки 2338.
Запрос с широким планом занимает 0,136 секунды, а запрос с узким планом — всего 0,112 секунды. Две длительности очень близки, и обновление Per-Index (широкий план) менее полезно, так как данные уже находятся в буфере до
UPDATEвыполнения инструкции.На следующем снимке экрана показаны широкие и узкие планы при кэшировании данных в буферном пуле:


Данные не кэшируются в буферном пуле
Чтобы проверить, работает ли широкий план быстрее узкого плана, если данные не содержатся в буферном пуле, выполните следующие запросы:
Примечание.
При выполнении теста убедитесь, что ваша рабочая нагрузка является единственной рабочей нагрузкой в SQL Server, а диски выделены для SQL Server.
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 seconds
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 8790) --force Wide plan
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 SECONDS
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 2338) --force Narrow plan
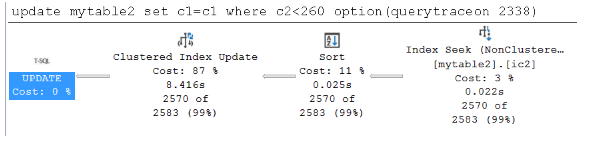
Запрос с широким планом занимает 3,554 секунды, а запрос с узким планом — 6,701 секунды. На этот раз запрос с широким планом выполняется быстрее.
На следующем снимке экрана показан широкий план, если данные не кэшируются в буферном пуле:

На следующем снимке экрана показан узкий план, если данные не кэшируются в буферном пуле:
Является ли запрос широкого плана всегда быстрее, чем узкий план запроса, если данные не есть в буфере?
Ответ " не всегда". Чтобы проверить, выполняется ли запрос на широкий план всегда быстрее, чем узкий план запроса, если данные отсутствуют в буфере, выполните следующие действия.
Создайте другую таблицу ,
mytable2выполнив следующие команды:SELECT c1,c1 AS c2,c1 AS C3,c1 AS c4,c1 AS C5 INTO mytable3 FROM mytable2 GO CREATE CLUSTERED INDEX IC1 ON mytable3(C1) CREATE INDEX IC2 ON mytable3(C2) CREATE INDEX IC3 ON mytable3(C3) CREATE INDEX IC4 ON mytable3(C4) CREATE INDEX IC5 ON mytable3(C5) GOТо
mytable3же, что иmytable2, за исключением данных.mytable3содержит все пять столбцов с одинаковым значением, что делает порядок некластикционных индексов следовать порядку кластеризованного индекса. Такая сортировка данных позволит свести к минимуму преимущество широкого плана.Выполните следующие команды, чтобы сравнить планы запросов:
CHECKPOINT GO DBCC DROPCLEANBUFFERS go UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 8790) --tf 8790 will force Wide plan CHECKPOINT GO DBCC DROPCLEANBUFFERS GO UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 2338) --tf 2338 will force Narrow planДлительность обоих запросов значительно сокращается! Широкий план занимает 0,304 секунды, что немного медленнее, чем узкий план на этот раз.
На следующем снимку экрана показано сравнение производительности при использовании широких и узких значений:


Сценарии, в которых применяются широкие планы
Ниже приведены другие сценарии, в которых применяются также широкие планы.
Столбец кластеризованного индекса имеет уникальный или первичный ключ, а несколько строк обновляются.
Ниже приведен пример воспроизведения сценария:
CREATE TABLE mytable4(c1 INT primary key,c2 INT,c3 INT,c4 INT)
GO
CREATE INDEX ic2 ON mytable4(c2)
CREATE INDEX ic3 ON mytable4(c3)
CREATE INDEX ic4 ON mytable4(c4)
GO
INSERT mytable4 VALUES(0,0,0,0)
INSERT mytable4 VALUES(1,1,1,1)
На следующем снимку экрана показано, что общий план используется, если индекс кластера имеет уникальный ключ:

Дополнительные сведения см. в статье Обслуживание уникальных индексов.
Столбец индекса кластера указан в схеме секционирования
Ниже приведен пример воспроизведения сценария:
CREATE TABLE mytable5(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS1')
DROP PARTITION SCHEME PS1
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF1')
DROP PARTITION FUNCTION PF1
GO
CREATE PARTITION FUNCTION PF1(INT) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS1 AS
PARTITION PF1 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable5(c1) ON PS1(c1)
CREATE INDEX c2 ON mytable5(c2)
CREATE INDEX c3 ON mytable5(c3)
CREATE INDEX c4 ON mytable5(c4)
GO
UPDATE mytable5 SET c1=c1 WHERE c1=1
На следующем снимке экрана показано, что широкий план используется при наличии кластеризованного столбца в схеме секционирования:

Столбец кластеризованных индексов не является частью схемы секционирования, и столбец схемы секционирования обновляется.
Ниже приведен пример воспроизведения сценария:
CREATE TABLE mytable6(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS2')
DROP PARTITION SCHEME PS2
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF2')
DROP PARTITION FUNCTION PF2
GO
CREATE PARTITION FUNCTION PF2(int) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS2 AS
PARTITION PF2 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable6(c1) ON PS2(c2) --on c2 column
CREATE INDEX c3 ON mytable6(c3)
CREATE INDEX c4 ON mytable6(c4)
На следующем снимку экрана показано, что при обновлении столбца схемы секционирования используется широкий план:

Заключение
SQL Server выбирает широкое обновление плана при одновременном выполнении следующих условий:
- Затронуто число строк больше 250.
- Память конечного индекса составляет не менее 1/1000 параметра max server memory.
Широкие планы повышают производительность за счет использования дополнительной памяти.
Если ожидаемый план запроса не используется, это может быть вызвано устаревшей статистикой (не сообщается о правильном размере данных), параметром максимальной памяти сервера или другими несвязанными проблемами, такими как планы с учетом параметров.
Длительность инструкций
UPDATE, использующих широкий план, зависит от нескольких факторов, и в некоторых случаях это может занять больше времени, чем узкие планы.Флаг трассировки 8790 будет принудительно использовать широкий план; Флаг трассировки 2338 будет принудительно использовать узкий план.