Функции потоков данных уровня "Премиум"
Потоки данных поддерживаются для пользователей Power BI Pro, Premium на пользователя (PPU) и Power BI Premium. Некоторые функции доступны только с подпиской Power BI Premium (которая является лицензией уровня Premium или PPU). В этой статье описаны и подробно описаны функции PPU и premium и их использование.
Следующие функции доступны только в подписке на емкость Power BI Premium (PPU или premium):
- Расширенный вычислительный модуль
- DirectQuery
- Вычисляемых сущностей
- Связанные сущности
- Добавочное обновление
В следующих разделах подробно описаны все эти функции.
Внимание
Эта статья относится к первому поколению потоков данных (1-го поколения) и не применяется ко второму поколению потоков данных (2-го поколения), которые доступны в Microsoft Fabric (предварительная версия). Дополнительные сведения см. в статье "Получение из потоков данных поколения 1 в потоки данных 2-го поколения".
Расширенный подсистема вычислений
Расширенный вычислительный механизм в Power BI позволяет подписчикам Power BI Premium использовать свою емкость для оптимизации использования потоков данных. Использование расширенного подсистемы вычислений обеспечивает следующие преимущества:
- Значительно сокращает время обновления, необходимое для длительных операций ETL (извлечение, преобразование, загрузка) для вычисляемых сущностей, таких как выполнение соединений, отдельных, фильтров и группирования по.
- Выполняет запросы DirectQuery по сущностям.
Примечание.
- Процессы проверки и обновления информируют потоки данных схемы модели. Чтобы задать схему таблиц самостоятельно, используйте Редактор Power Query и задайте типы данных.
- Эта функция доступна во всех кластерах Power BI, кроме WABI-INDIA-CENTRAL-A-PRIMARY
Включение расширенного вычислительного модуля
Внимание
Расширенный вычислительный модуль работает только для емкостей A3 или более крупных емкостей Power BI.
В Power BI Premium расширенный вычислительный модуль настраивается отдельно для каждого потока данных. Выбрать один из трех конфигураций:
Отключен
Оптимизировано (по умолчанию) — расширенная подсистема вычислений отключена. Он автоматически включается, когда таблица в потоке данных ссылается на другую таблицу или когда поток данных подключен к другому потоку данных в той же рабочей области.
Вкл.
Чтобы изменить параметр по умолчанию и включить расширенный вычислительный модуль, выполните следующие действия.
В рабочей области рядом с потоком данных, для которого нужно изменить параметры, выберите "Дополнительные параметры".
В меню "Дополнительные параметры потока данных" выберите Параметры.
Разверните параметры расширенного вычислительного ядра.
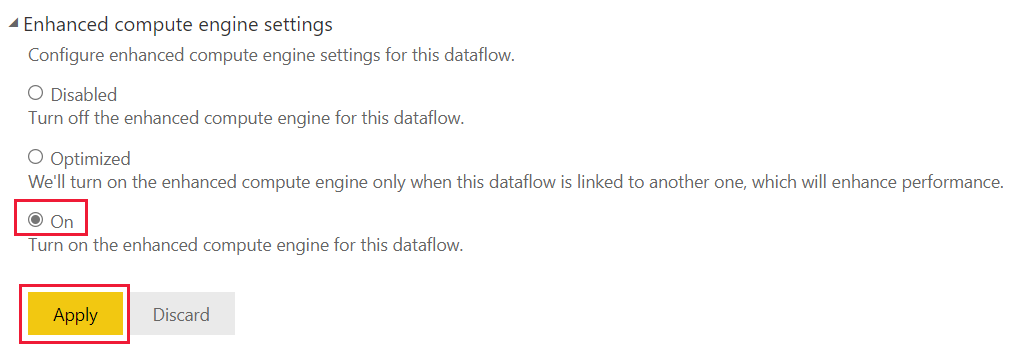
В параметрах расширенного вычислительного ядра нажмите кнопку "Вкл." и нажмите кнопку "Применить".
Использование расширенного подсистемы вычислений
После включения расширенного вычислительного модуля вернитесь к потокам данных и вы увидите улучшение производительности в любой вычисляемой таблице, которая выполняет сложные операции, такие как соединения или группы по операциям для потоков данных, созданных из существующих связанных сущностей в той же емкости.
Чтобы лучше использовать подсистему вычислений, разделите этап ETL на два отдельных потока данных следующим образом:
- Поток данных 1 . Этот поток данных должен принимать только все необходимые данные из источника данных.
- Поток данных 2 . Выполнение всех операций ETL в этом втором потоке данных, но убедитесь, что вы ссылаетесь на поток данных 1, который должен находиться в одной емкости. Кроме того, необходимо выполнить операции, которые могут сначала сложить: фильтр, группировать по, отличаться, присоединиться). И выполните эти операции перед любой другой операцией, чтобы убедиться, что подсистема вычислений используется.
Общие вопросы и ответы
Вопрос. Я включил расширенный вычислительный модуль, но мои обновления медленнее. Почему?
Ответ. Если включить расширенный вычислительный модуль, существует два возможных объяснения, которые могут привести к более медленному времени обновления:
Если расширенный вычислительный модуль включен, для правильной работы требуется некоторая память. Таким образом, объем памяти, доступный для выполнения обновления, уменьшается и, следовательно, увеличивает вероятность очередей обновлений. Это увеличение уменьшает количество потоков данных, которые могут одновременно обновляться. Чтобы устранить эту проблему, при включении расширенных вычислений распространение обновлений потока данных с течением времени и оценить, подходит ли размер емкости, чтобы обеспечить доступность памяти для одновременных обновлений потока данных.
Другая причина, по которой может возникнуть более медленное обновление, заключается в том, что подсистема вычислений работает только над существующими сущностями. Если поток данных ссылается на источник данных, который не является потоком данных, вы не увидите улучшения. В некоторых сценариях больших данных не будет увеличиваться производительность, так как начальное чтение из источника данных будет медленнее, так как данные необходимо передать в расширенный вычислительный механизм.
Вопрос. Я не вижу переключения расширенного вычислительного модуля. Почему?
Ответ. Расширенный вычислительный механизм выпускается на этапах для регионов по всему миру, но пока не доступен в каждом регионе.
Вопрос. Каковы поддерживаемые типы данных для подсистемы вычислений?
Ответ. Расширенный вычислительный модуль и потоки данных в настоящее время поддерживают следующие типы данных. Если поток данных не использует один из следующих типов данных, во время обновления возникает ошибка:
- Дата/время
- Десятичное число
- Текст
- Целое число
- Дата/часовой пояс
- Истина/ложь
- Дата
- Время
Использование DirectQuery с потоками данных в Power BI
Вы можете использовать DirectQuery для подключения непосредственно к потокам данных и таким образом подключаться непосредственно к потоку данных без необходимости импортировать свои данные.
Использование DirectQuery с потоками данных позволяет улучшить процессы Power BI и потоков данных:
Избегайте отдельных расписаний обновления. DirectQuery подключается непосредственно к потоку данных, удаляя необходимость создания импортированной семантической модели. Таким образом, использование DirectQuery с потоками данных означает, что вам больше не нужны отдельные расписания обновления для потока данных и семантической модели, чтобы убедиться, что данные синхронизированы.
Фильтрация данных — DirectQuery полезна для работы с отфильтрованным представлением данных внутри потока данных. DirectQuery можно использовать с подсистемой вычислений для фильтрации данных потока данных и работы с отфильтрованным подмножеством. Фильтрация данных позволяет работать с меньшим и более управляемым подмножеством данных в потоке данных.
Использование DirectQuery для потоков данных
Использование DirectQuery с потоками данных доступно в Power BI Desktop.
Существуют необходимые условия для использования DirectQuery с потоками данных:
- Поток данных должен находиться в рабочей области с поддержкой Power BI Premium.
- Подсистема вычислений должна быть включена.
Дополнительные сведения о DirectQuery с потоками данных см. в статье Использование DirectQuery с потоками данных.
Включение DirectQuery для потоков данных
Чтобы обеспечить доступность потока данных для доступа DirectQuery, расширенный вычислительный модуль должен находиться в оптимизированном состоянии. Чтобы включить DirectQuery для потоков данных, задайте для нового параметра расширенных параметров подсистемы вычислений значение "Вкл.".

После применения этого параметра обновите поток данных, чтобы оптимизация вступила в силу.
Рекомендации и ограничения для DirectQuery
Существует несколько известных ограничений с DirectQuery и потоками данных:
Составные и смешанные модели с источниками данных DirectQuery в настоящее время не поддерживаются.
Большие потоки данных могут столкнуться с проблемами времени ожидания при просмотре визуализаций. Большие потоки данных, которые возникают с проблемами времени ожидания, должны использовать режим импорта.
В параметрах источника данных соединитель потока данных будет отображать недопустимые учетные данные, если вы используете DirectQuery. Это предупреждение не влияет на поведение, и семантическая модель будет работать правильно.
Если поток данных содержит 340 столбцов или более, использование соединителя потока данных в Power BI Desktop с включенным параметром расширенного вычислительного модуля приводит к отключению параметра DirectQuery для потока данных. Чтобы использовать DirectQuery в таких конфигурациях, используйте менее 340 столбцов.
Вычисляемых сущностей
При использовании потоков данных с подпиской Power BI Premium можно выполнять вычисления в хранилище. Эта функция позволяет выполнять вычисления существующих потоков данных и возвращать результаты, позволяющие сосредоточиться на создании отчетов и аналитике.
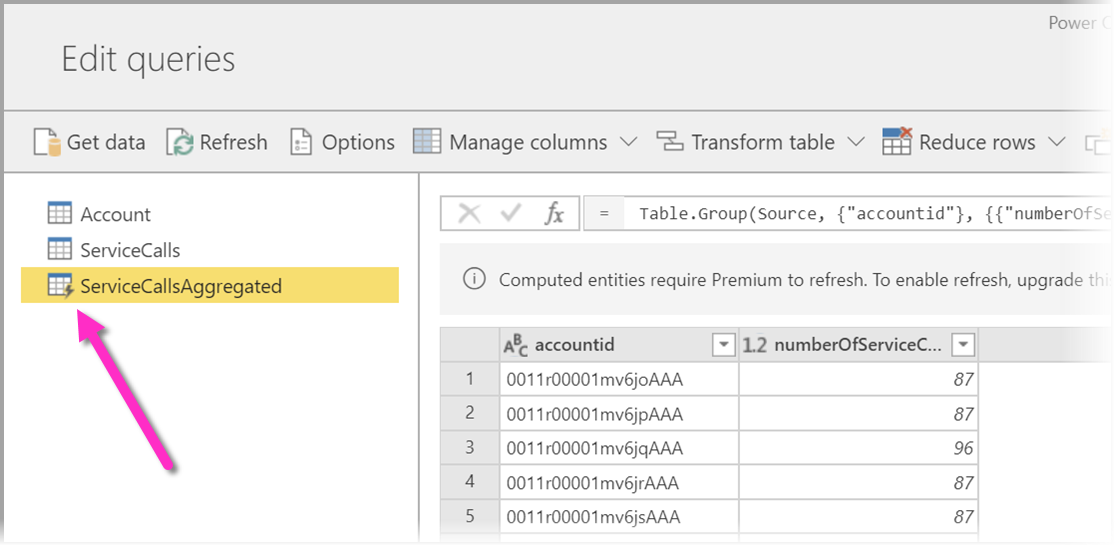
Для выполнения вычислений в хранилище сначала необходимо создать поток данных и перенести данные в хранилище потоков данных Power BI. После создания потока данных, содержащего данные, можно создать вычисляемые сущности, которые являются сущностями, выполняющими вычисления в хранилище.
Рекомендации и ограничения вычислительных сущностей
- При работе с потоками данных, созданными в учетной записи Azure Data Lake Storage 2-го поколения организации, связанные сущности и вычислительные сущности работают правильно, если сущности находятся в той же учетной записи хранения.
В качестве рекомендации при вычислении данных, присоединенных к локальным и облачным данным, создайте новый поток данных для каждого источника (один для локальной среды и один для облака), а затем создайте третий поток данных для слияния или вычисления по этим двум источникам данных.
Связанные сущности
Вы можете ссылаться на существующие потоки данных с помощью связанных сущностей с подпиской Power BI Premium, что позволяет выполнять вычисления для этих сущностей с помощью вычисляемых сущностей или создавать таблицу "один источник истины", которую можно повторно использовать в нескольких потоках данных.
Добавочное обновление
Потоки данных можно задать для обновления постепенно, чтобы избежать необходимости извлекать все данные при каждом обновлении. Для этого выберите поток данных, а затем щелкните значок добавочного обновления.

Параметр добавочного обновления добавляет параметры в поток данных, чтобы указать диапазон дат. Подробные сведения о настройке добавочного обновления см. в разделе"Использование добавочного обновления с потоками данных".
Рекомендации по настройке добавочного обновления
Не устанавливайте поток данных для добавочного обновления в следующих ситуациях:
- Связанные сущности не должны использовать добавочное обновление, если они ссылаются на поток данных.
Связанный контент
Дополнительные сведения о потоках данных и Power BI см. в следующих статьях.