Анализ данных с помощью машинного обучения Azure
В этом учебнике показано, как построить прогнозную модель машинного обучения с помощью конструктора Машинного обучения Azure. Эта модель основана на данных, хранящихся в Azure Synapse. Сценарий в учебнике состоит в том, чтобы предсказать, купит ли клиент велосипед, чтобы магазин велосипедов Adventure Works мог создать таргетированную маркетинговую кампанию.
Предварительные требования
Для пошагового изучения этого учебника потребуется следующее:
- Пул SQL, в который предварительно загружены демонстрационные данные AdventureWorksDW. Чтобы подготовить этот пул SQL, выберите загрузку демонстрационных данных и следуйте указаниям, приведенным в статье Создание пула SQL. Если хранилище данных уже существует, но в нем нет демонстрационных данных, вы можете загрузить их вручную.
- Рабочая область Машинного обучения Azure. Чтобы создать ее, следуйте указаниям в этом учебнике.
Получение данных
Используемые данные находятся в представлении dbo.vTargetMail в AdventureWorksDW. Чтобы можно было использовать хранилище данных в этом учебнике, данные сначала экспортируются в учетную запись Azure Data Lake Storage, так как Azure Synapse в настоящее время не поддерживает наборы данных. Для экспорта данных из хранилища данных в Azure Data Lake Storage с помощью действия копирования можно использовать Фабрику данных Azure. Используйте следующий запрос для импорта:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Когда данные станут доступны в Azure Data Lake Storage, хранилища данных в Машинном обучении Azure можно будет использовать для подключения к службам хранилища Azure. Выполните следующие действия, чтобы создать хранилище данных и соответствующий набор данных.
Запустите Студию машинного обучения Azure на портале Azure или войдите в Студию машинного обучения Azure.
В левой области в разделе Управление щелкните Хранилища данных, а затем щелкните Новое хранилище данных.
Укажите имя хранилища данных, выберите тип "Хранилище BLOB-объектов Azure", укажите расположение и учетные данные. Затем нажмите кнопку Создать.
В левой области в разделе Ресурсы щелкните Наборы данных. Выберите Создать набор данных с параметром Из хранилища данных.
Укажите имя набора данных и выберите тип Таблицы. Затем нажмите кнопку Далее, чтобы продолжить.
В разделе Select or create a datastore (Выбор или создание хранилища данных) выберите параметр Созданное ранее хранилище данных. Выберите созданное ранее хранилище данных. Нажмите кнопку "Далее" и укажите параметры пути и файлов. Обязательно укажите заголовок столбца, если файлы содержат его.
Наконец, нажмите кнопку Создать, чтобы создать набор данных.
Настройка эксперимента в конструкторе
Теперь выполните следующие действия для настройки конструктора:
В левой области в разделе Автор щелкните вкладку Конструктор.
Выберите Удобные готовые компоненты, чтобы создать конвейер.
В области параметров справа укажите имя конвейера.
Кроме того, выберите целевой вычислительный кластер для всего эксперимента с помощью кнопки "Параметры", указав подготовленный ранее кластер. Закройте панель Параметры.
Импорт данных
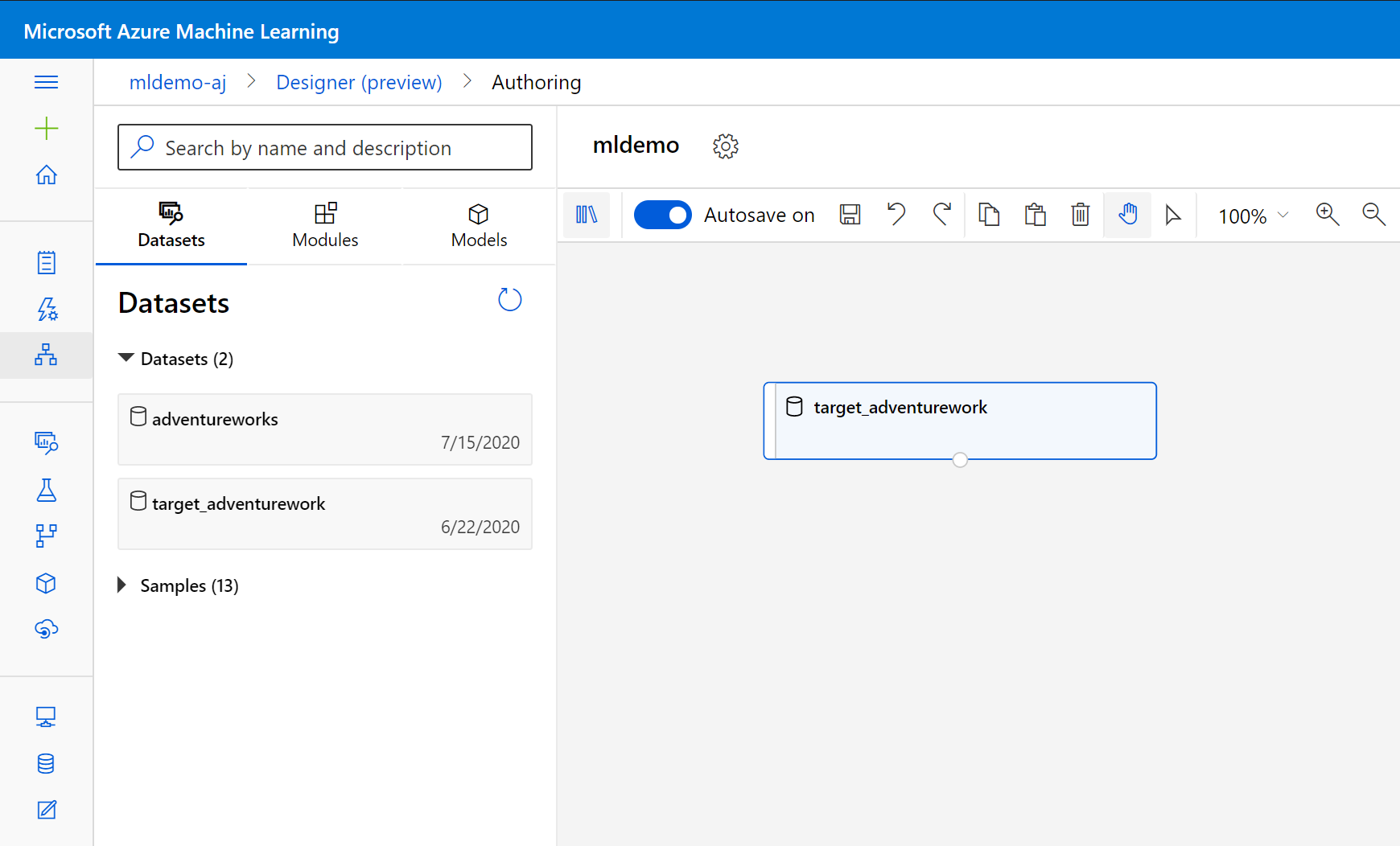
В области слева под полем поиска выберите вкладку Наборы данных.
Перетащите созданный ранее набор данных на холст.
Очистка данных
Чтобы очистить данные, удалите столбцы, которые не являются значимыми для этой модели. Выполните инструкции, описанные ниже.
Выберите в области слева подвкладку Компоненты.
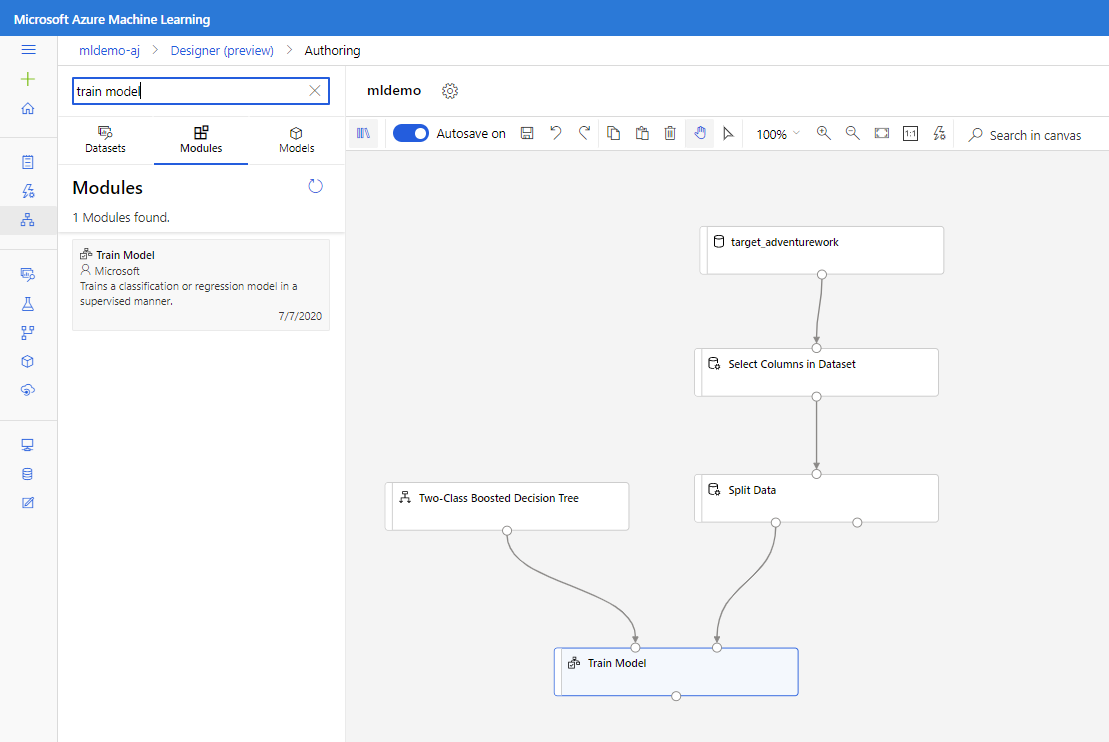
В разделе Преобразование данных < Манипуляции перетащите компонент Выбор столбцов в наборе данных на холст. Подключите этот компонент к компоненту Набор данных.
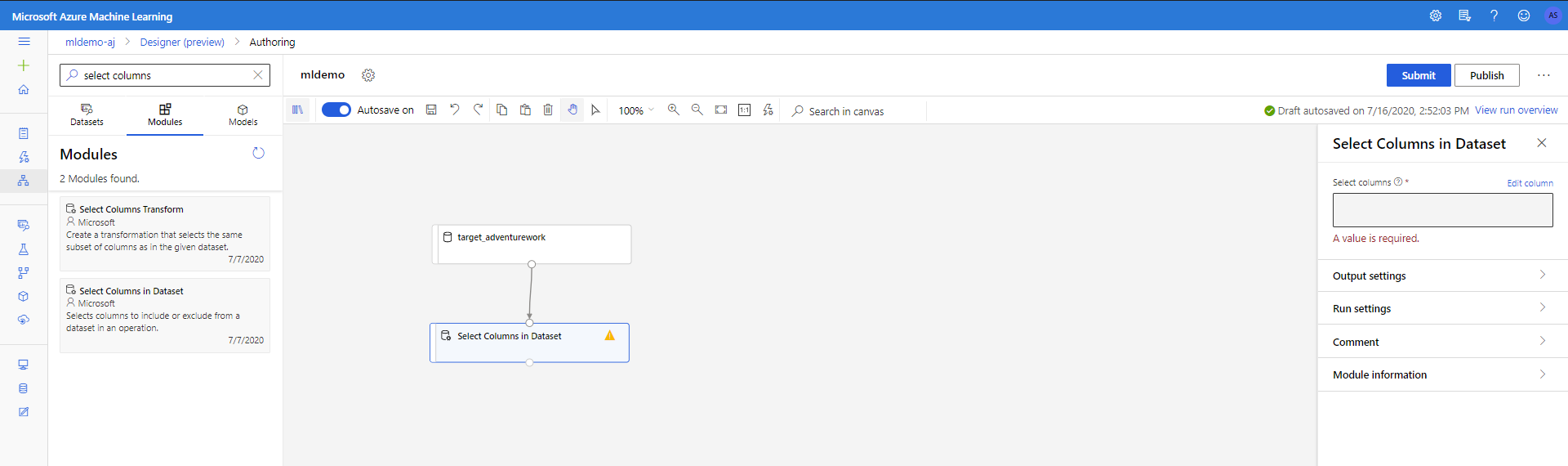
Щелкните компонент, чтобы открыть область свойств. Щелкните "Изменить столбец", чтобы указать столбцы, которые вы хотите удалить.
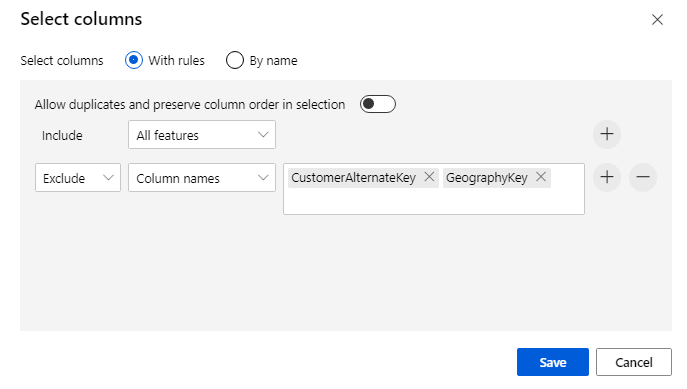
Исключите два столбца. CustomerAlternateKey и GeographyKey. Нажмите кнопку Сохранить

Создание модели
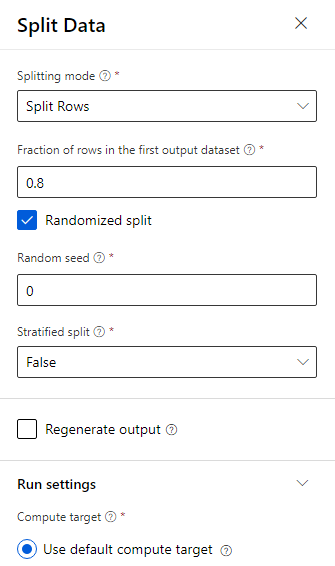
Данных разделяются в соотношении 80 к 20: 80 % для подготовки модели машинного обучения и 20 % для проверки модели. Для этой задачи двоичной классификации используются двухклассовые алгоритмы.
Перетащите компонент Разделение данных на холст.
В области свойств в поле Доля строк в первом наборе выходных данных введите значение 0,8.
Перетащите компонент Двухклассовое увеличивающееся дерево принятия решений на холст.
Перетащите компонент Обучение модели на холст. Укажите входные данные, подключив его к компонентам Двухклассовое увеличивающееся дерево решений (алгоритм машинного обучения) и Разделение данных (данные для обучения алгоритма).
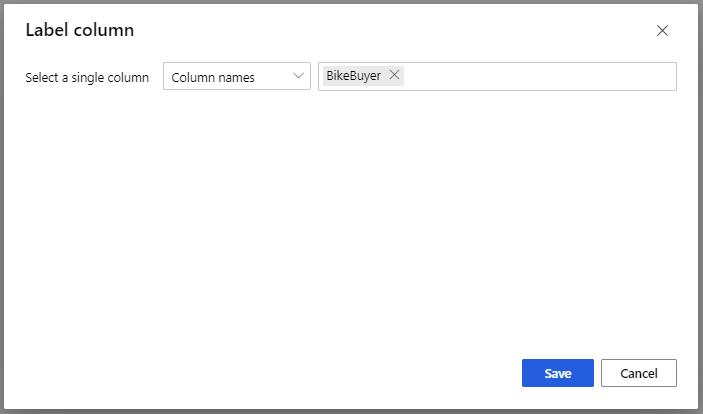
Для модели "Обучение модели" для параметра Столбец метки в области "Свойства "выберите "Изменить столбец". Выберите столбец BikeBuyer в качестве прогнозируемого и щелкните Сохранить.
Оценка модели
Теперь протестируйте модель на тестовых данных. Будут сравниваться два разных алгоритма, чтобы узнать, какой из них лучше. Выполните инструкции, описанные ниже.
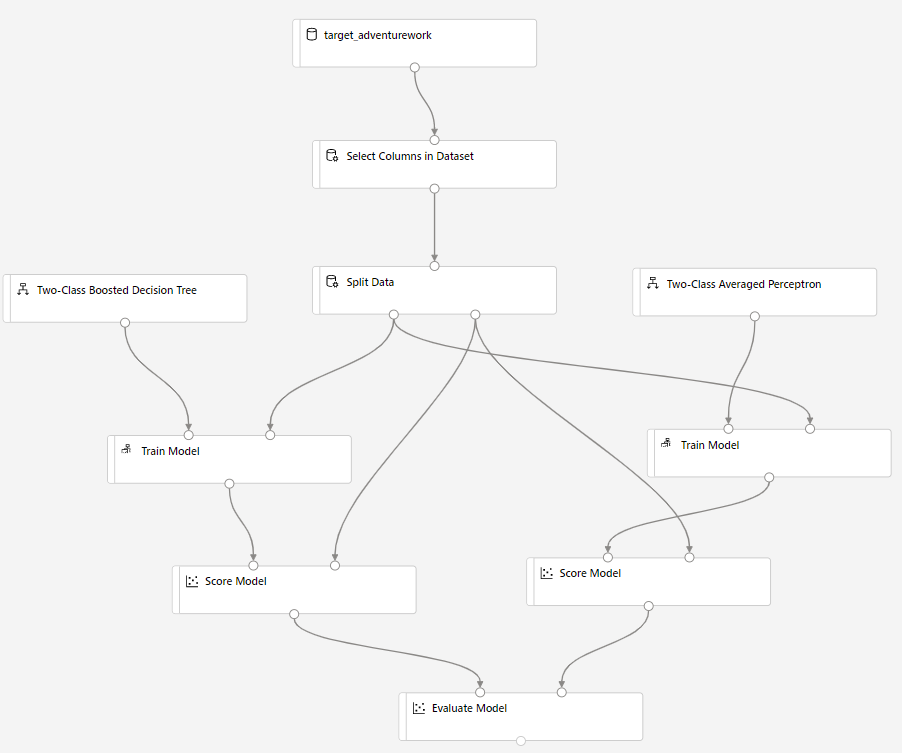
Перетащите компонент Оценка модели на холст и подключите его к компонентам Обучение модели и Разделение данных.
Перетащите на холст эксперимента модуль Two-Class Bayes Averaged Perceptron (Двухклассовый усредненный перцептрон Байеса). Мы сравним эффективность этого алгоритма и алгоритма двухклассового увеличивающегося дерева принятия решений.
Скопируйте и вставьте компоненты Обучение модели и Оценка модели на холст.
Перетащите компонент Оценка модели на холст для сравнения двух алгоритмов.
Нажмите кнопку Отправить, чтобы настроить выполнение конвейера.
После завершения выполнения щелкните правой кнопкой мыши компонент Оценка модели и выберите Визуализировать результаты оценки.
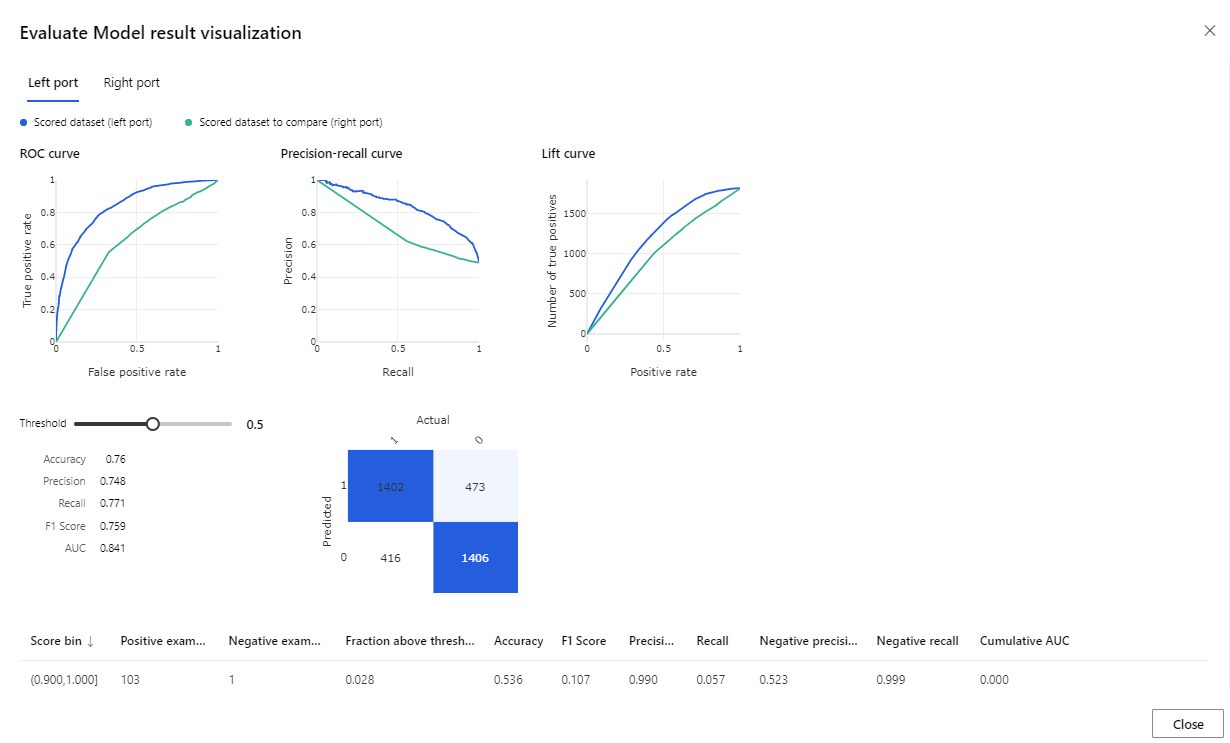

Отображенные метрики представляют собой ROC-кривую, lift-кривую, а также диаграмму соотношения полноты и точности. При изучении этих метрик становится понятно, что первая модель является более эффективной, чем вторая. Чтобы просмотреть прогнозы первой модели, щелкните правой кнопкой мыши компонент "Оценка модели" и выберите "Визуализировать оцененный набор данных", чтобы увидеть прогнозируемые результаты.
Вы увидите два дополнительных столбца, добавленные в тестовый набор данных.
- Оценка вероятности: вероятность того, что клиент является покупателем велосипеда.
- Метка оценки: выполненная моделью классификация — покупатель велосипеда (1) или нет (0). Порог вероятности для маркировки равен 50 % и может быть изменен.
Сравнение столбца BikeBuyer (фактическое значение) и столбца "Scored Labels" (Метки оценки) (прогнозное значение) позволяет оценить эффективность выполнения модели. Эту модель затем можно использовать, чтобы делать прогнозы для новых клиентов. Вы можете опубликовать эту модель как веб-службу или записывать результаты в Azure Synapse.
Дальнейшие действия
Дополнительные сведения о Машинном обучении Azure см. в статье Введение в машинное обучение в Azure.
Дополнительные сведения о встроенных оценках в хранилище данных см. здесь.